Counting Unique users in Realtime stream using Redis with low memory usage
If you have a real-time application using any stream e.g Kafka and processed using Apache Storm/Spark/Flink and you want to keep track of a million unique users for some time range ( eg. 10 min, 30 min or 1h) then doing it using Set or any other cache inside code becomes very memory extensive operation.
Also, it becomes tricky when you have distributed processing and keep track of unique users across all nodes. Your spark/storm stream runs on multiple instances.
What you really want when dealing with enormous datasets is something with predictable storage and performance characteristics.
That is precisely what HyperLogLog (HLL) is — an algorithm optimized for counting the distinct values within a stream of data.
Enormous streams of data. It is an algorithm that has become invaluable for real-time analytics.
The Hyper LogLog Counter’s name is self-descriptive.
The name comes from the fact that you can estimate the cardinality of a set with cardinality Nmax using just loglog(Nmax) + O(1) bits.
The HyperLogLog algorithm is able to estimate cardinalities of > 10⁹ with a typical accuracy of 2%, using 1.5 kB of memory.
HyperLogLog is an extension of the earlier LogLog algorithm.
Redis Hyperloglog commands:
There are three commands to make all hyperloglog operations possible.
PFADD
PFCOUNT
PFMERGE
The commands are prefixed with PF to honor the author of LogLog Philippe Flajolet.
Lest see how to use PFADD and PFCOUNT to count distinct.
Open you redis-cli and Try below commands.
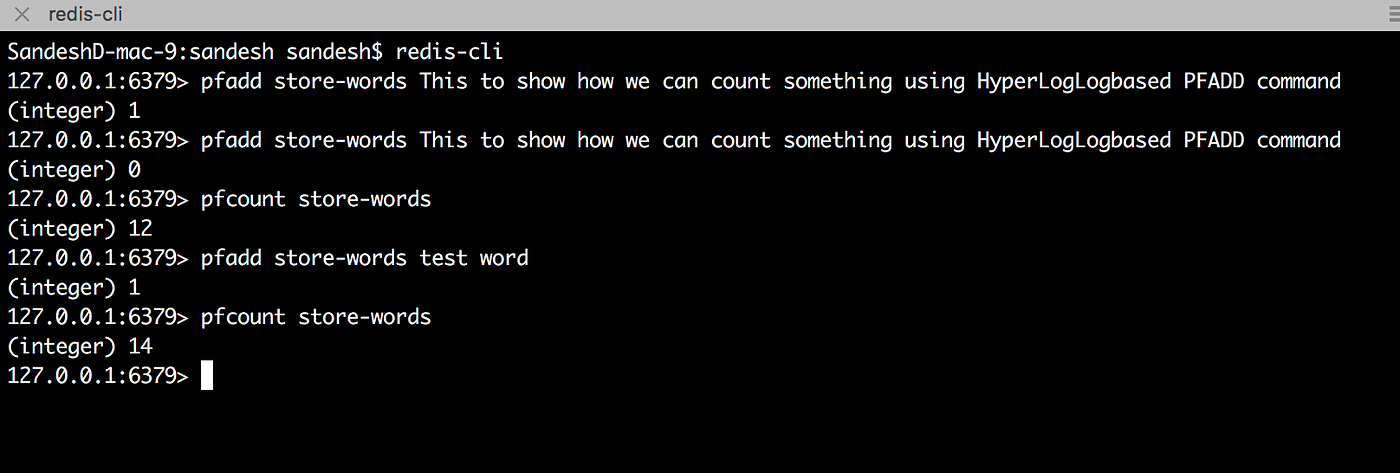
What we have done here is we have created key store-words to store the words using pfadd command and count distinct using pfcount command

We can also create new key store-new-words and store data in there.
we call PFCOUNT with multiple keys, which merges the structures in memory and gives us the combined cardinality.
What is the use of counting multiple keys?
A simple example is if you have real-time stream processing like spark/storm and you need to count/share 10min unique users
and hourly unique users etc.
You can store userids in keys like YMD-H-1OminIndex. in an hour we can have 6 indexes like 0,1,2,3,4,5
Each represents 10 min duration. e.g. 0 means 0 minutes to the end of 9 minutes. 1 means 10 th Minute to end of 19 th Minute etc
So, we will have keys like 20190130–12–0,20190130–12–1,20190130–12–2,20190130–12–3,20190130–12–4,20190130–12–5
We will store the users in redis using PFADD in above keys.
if you want to count 10 mins distinct visitors/users just use a command like pfcount 20190130–12–0
if you want to see what are distinct users/visitors in an hour then use a command like pfcount 20190130–12–0,20190130–12–1,20190130–12–2,20190130–12–3,20190130–12–4,20190130–12–5
it will give distinct/unique visitor in that hour.
Sample code to do this is here:

